
In today’s digital landscape, we handle large volumes of text daily. As developers, it’s crucial to grasp how text is encoded to ensure proper interpretation across systems. Even if it’s not something you will get asked directly in a system design interview, this knowledge is key to conscientious development.
If everything in computers is binary, how do we turn binary into text?
ASCII (American Standard Code for Information Interchange):
- it is a character encoding standard used in computers and communication equipment to represent text and control characters
- assigns a unique numerical value to each character, such as letters, numbers, punctuation marks, and special symbols
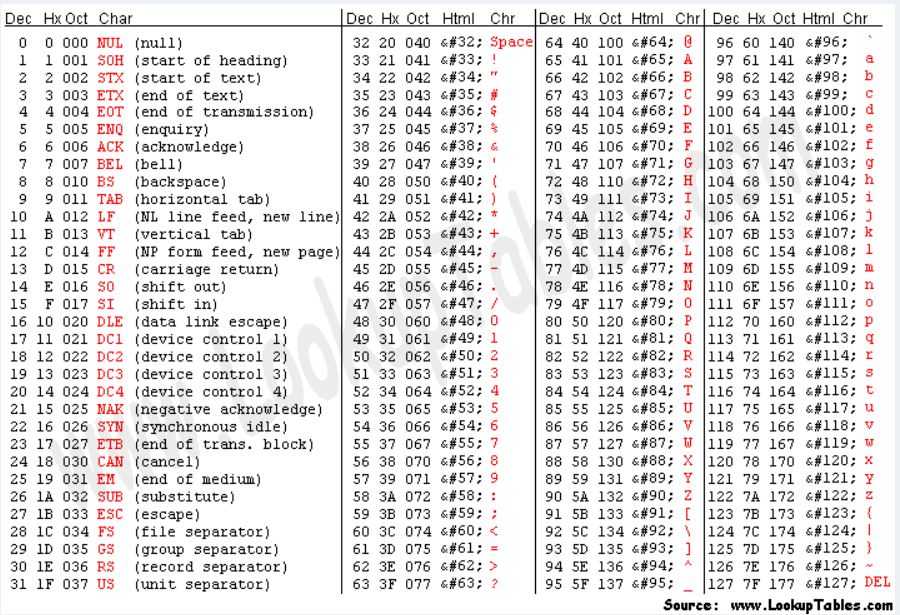
- each character is represented by a 7-bit binary number, allowing for a total of 128 possible characters. One byte can fit every English character and control characters (which were useful long time ago e.g 7 makes your computer do bee bee)
Problems with ascii
ASCII have only 127 characters and one byte allow us to encode 255 characters. What to do with values from 127 to 255? Everyone had their own ideas how to use those remaining values e.g. to encode characters that appear in non-Latin alphabets. We call all those different encodings for ASCII codepages. There are over 465 different codepages, often multiple of them for a single language.
That’s how we ended up with lots of different encodings depending on the language and with the spread of the Internet, it was necessary to propose a different solution. This is how we get to Unicode.
Unicode
- Unicode (Universal Coded Character Set (UCS)) is a character encoding standard that aims to represent text from all writing systems used worldwide consistently
- it defines so-called code points that are, mappings of characters to keys that any computer can refer to. A collection of such code points is called a character set, hence the name.
- e.g: U+0048: LATIN CAPITAL LETTER H
- U+ – informs us that this is the unicode standard
- 0048 – what results when the binary gets transformed to numbers (in hexadecimal – simpler way of representing binary numbers)
- at this address you can find all current character to code point mappings: Code Points Mapping Table
- Unicode is not finished, and we have a new release every 1/2 years – Unicode Releases
�? – U+FFFD, the Replacement Character, is simply another code point in the Unicode table. We can use it when they detect Unicode errors.
At this point we have a huge collection of code points mapping to characters, but it’s not enough. We need a way to encode it and here comes UTF.
The Role of UTF (Unicode Transformation Protocol):
- it’s a family of encoding schemes that implements the Unicode standard for character encoding. It tells how we store code points in memory.
- UTF encodings allow computers to represent and manipulate text in various languages and writing systems.
- there are different types of UTF, depending on the amount of bytes used to encode one code point
- UTF-8 – one byte per code point, most popular in internet, default for html 5. UTF-8 is backward compatible with ASCII, meaning that ASCII characters are represented using a single byte (the same as in ASCII) U+0041 (A, Latin Capital Letter A) is just 41, one byte.
- UTF-16 – two bytes
- UTF-32 – four bytes
- Depending on the language, we will need a different number of bytes to encode all the characters (variable length):
- English 1 byte
- European (Latin), Hebrew, Arabic – 2B
- Chinese, Japanese, Korean, other asian and emoji – 3B/4B
But how do I know what encoding is used in a given file?
- BOM – Byte Order Mark (Encoding Signature) – 2 bytes maker at the beginning of the file that tells what encoding the file is using.
- We can check what encoding was used on the page under the tag “““, and in HTTTP headers in section content-type
General workflow of decoding text file
Workflow:
- Identify encoding by reading the BOM (Byte Order Mark) at the file’s start.
- Decode the file into Unicode code points.
- Render Unicode characters onto the screen.

What if in the text, which is mostly in English and encoded in UTF-8, we need characters that require more bytes to encode?
- if we need a character that is encoded in a larger number of bytes, we can simply use an appropriate sequence of bits which indicate that subsequent bytes should be included in reading a given code point. Thanks to this we can have combinations of different characters in our single document
What will happen if I decode text with wrong character encoding?
- Decoding text with the wrong character encoding results in gibberish text known as Mojibake (jap. “character transformation”), where symbols are systematically replaced with unrelated ones.
A task for those willing. Check what this code – U+1F4A9 means in unicode :).


